summary: Um alle Rechnungen, Verträge, Dokumente, Eingangspost, Zertifikate und Zeugnisse zu verwalten, habe ich mir openpaper.work angesehen und setze es nun ein.
Warum ein DMS für private Zwecke?
Ich möchte alle eingehenden Dokumente einfach an einer Stelle sortiert und schnell wiederauffindbar verwalten. Ausserdem möchte ich eine Volltextsuche über alle diese Dokumente durchführen können, sowie diese mit Stichworten taggen können. Das Dokumentdatum sollte auch als Filter-/Auswahlkriterium genutzt werden können.
Aktuell habe ich Verträge teils in Papierordnern (Altverträge, Zeugnisse etc.), teils bereits gescannt unter ~/Dokumente/vertraege (neuere Versicherungs-/Arbeitsverträge u. ä.), aber leider, z. B. Strom-/Gaslieferantenverträge, weil sie häufiger wechseln, nur unter ~/Dokumente/[JJJJ]/[JJJJMMTT_ArtderDokumenteImVerzeichnis] abgelegt.
Es befindet sich zwar alles an Dokumenten innerhalb meines Dokumenteverzeichnisses und sogar chronologisch abgelegt, aber nicht in einem Pfad, sondern etwas verteilt und nicht Volltext-indiziert und daher oft eher uneffizient auffindbar. Ich muss schon wissen, wo am besten wie und nach welchem Stichwort die Suche beginnen sollte.
Ausserdem möchte ich diesen Bereich dann auch verschlüsselt zusätzlich in die Cloud sichern und nicht nur verschlüsselt auf meine interne und externen Festplatten. Eine dieser verschlüsselten Platten ist zwar extern bei Vertrauenspersonen ausgelagert. Diese wird aber eher jährlich aktualisiert, um einen Datensupergau zu verhindern. Auf die anderen Platten sichere ich wöchentlich.
Softwareauswahl
Per Zufall ist mir über Mastodon ein Tröt zugelaufen (wer das hier nicht versteht sollte mal auf ruhr.social vorbeisurfen und sich mit dem Socialnetwork Mastodon, auf dem ich unterwegs bin, beschäftigen), der openpaper.work empfahl.
Ursprünglich wollte ich mit SANE als Scanmodul und Tesseract für das anschließende OCR (Text-/Zeichenerkennung) etwas handgestricktes für diese Zwecke nutzen, denn nach der Zeichenerkennung wären die PDF-Dateien, die ich gescannt hätte, auch durchsuchbar geworden, aber die Idee eines einfachen, freien DMS-Systems hatte für mich den Charm eines für diesen Zweck geschlossenen und vielleicht auch einfacher zu nutzenden Tools.
“Keep ist simpel, but not simpler” hätte Einstein dazu gesagt :-)
Installation
Die Installation als flatpak geht hervorragend einfach unter Ubuntu 18.04 LTS.
Die Projektseite ist hier und die Software hier zu finden.
Für Debian (>= jessie) und Ubuntu (>=16.04) gibt es einen eigenen Bereich, in dem die Vorgehensweise beschrieben ist.
Installation von Flatpak and den Sane-Utilities
Zunächst musste ich die Pakete für flatpak und sane installieren:
sudo apt install flatpak sane-utils
Danach muss der saned (sanedemon) auch aktiviert werden
Der Sanedemaon muss aktiviert und für lokale Verbindungen eingerichtet werden.
Dies geht fix mit den drei Befehlen hier:
sudo sh -c "echo 127.0.0.1 >> /etc/sane.d/saned.conf"
sudo systemctl enable saned.socket
sudo systemctl start saned.socket
Installation von Paperwork
Nun kann auch Paperwork installiert werden. Gilt für meinen lokalen User:
flatpak --user install https://builder.openpaper.work/paperwork_master.flatpakref
Programmstart von Paperwork
Der Programmstart geht einfach über ein Terminalfenster mit dem folgenden Befehl:
flatpak run work.openpaper.Paperwork
Nutzung openpaper.work
Das Programm erklärt sich nahezu von alleine, in dem man es einfach benutzt.
Hier ein Screenshot der Oberfläche, bei dem ich auf Scan oben rechts geklickt habe. Wenn mein Scanner aktiv ist, wird der dort angezeigt und ich kann dann das Scannen dort aktivieren. Bei vorhandenen PDF Dateien kann dort “import (file(s))” angewählt werden.
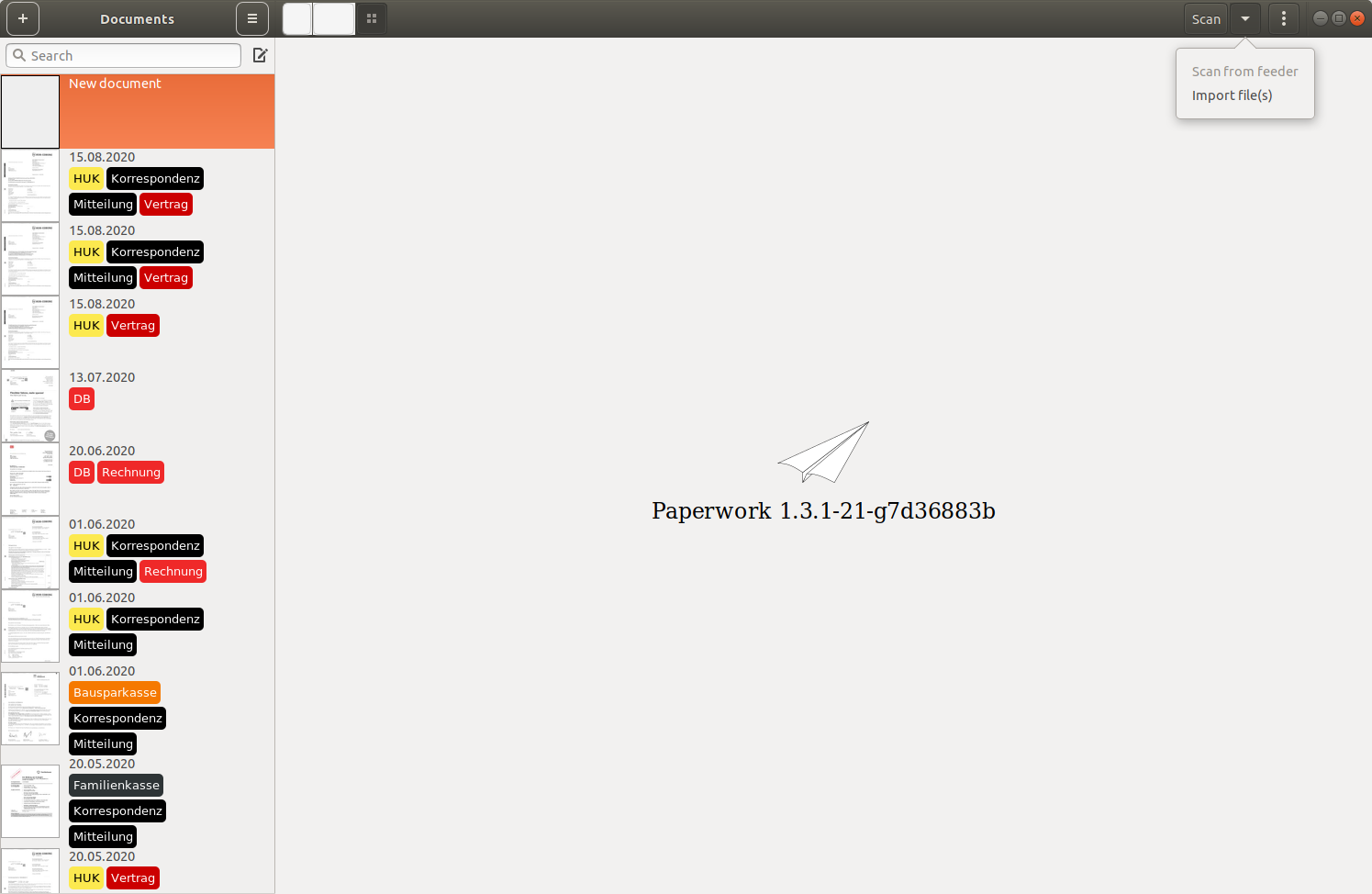
Dokumenteimport
Scan direkt aus openpaper.work
Über den Button “Scan” kann direkt nach openpaper.works gescannt werden.
Das OCR startet direkt im Anschluss.
Import bereits bestehender pdf-Files
Ebenfalls über den Button “Scan” kann dort über den Menüpunkt “Import File(s)” ein bestehendes pdf-File importiert werden.
Das OCR startet direkt im Anschluss.
Labeling / Tagging
In dem Screenshot oben ist zu sehen, dass man mehr als ausreichend lablen und taggen kann. Das Programm versucht die Labels sinnvoll vorzubelegen.
Datum setzen
Das Scan- oder Importdatum muss ja nicht dem Belegdatum entsprechen. Aus diesem Grund kann man das selbstverständlich entsprechend korrigieren.
Stichworte manuell vergeben
Falls das Labelling und die Suche nach den Beleginhalten nicht ausreichen sollte und man unbedingt Dokumenten noch Suchstichworte mitgeben möchte, so ist dies auch möglich.
Dokumente suchen und finden
Über die Search-Textbox kann man Suchbegriffe, die sich in den zu suchenden Dokumenten befinden könnten suchen.
Dokumente exportieren
Über die drei Punkte oben rechts kommt man zu den Einstellungen, aber auch in den Export-Bereich, um die Dokumente wieder als pdf-Dateien exportieren zu können.
Einfaches Backup der Daten
Die Dateien werden lokal abgelegt und können mit den üblichen Mitteln wie z. B. Syncthing oder Nextcloud auf andere Geräte oder den eigenen Webserver kopiert werden.
Das Verzeichnis sollte natürlich beim Backup berücksichtigt werden, um keinen Datenverlust durch defekte oder abhanden gekommende Hardware erleiden zu müssen.